我最近尝试用dqn构建一个国际象棋代理。
任何了解DQN和国际象棋的人都会告诉你这是个不太现实的想法。 确实如此,但作为一名初学者,我依然乐于尝试。本文将分享我的经验和心得。
环境理解
在实现代理之前,我需要熟悉环境并创建一个自定义包装器,以便在训练过程中与代理交互。
-
我使用了kaggle_environments库中的国际象棋环境。
from kaggle_environments import make env = make("chess", debug=True)登录后复制 -
我还使用了chessnut,一个轻量级的Python库,用于解析和验证国际象棋游戏。
from chessnut import game initial_fen = env.state[0]['observation']['board'] game = game(env.state[0]['observation']['board'])
登录后复制
环境状态表示
棋盘状态以FEN格式存储。
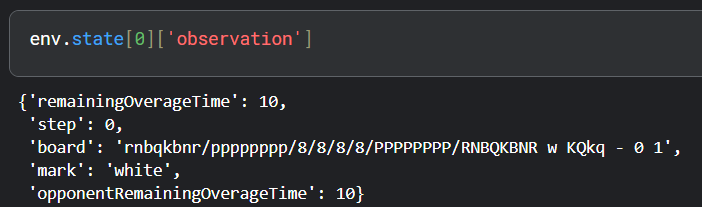
FEN是一种紧凑的棋盘表示方法。但为了神经网络的输入,我需要修改状态表示。
FEN转换为矩阵
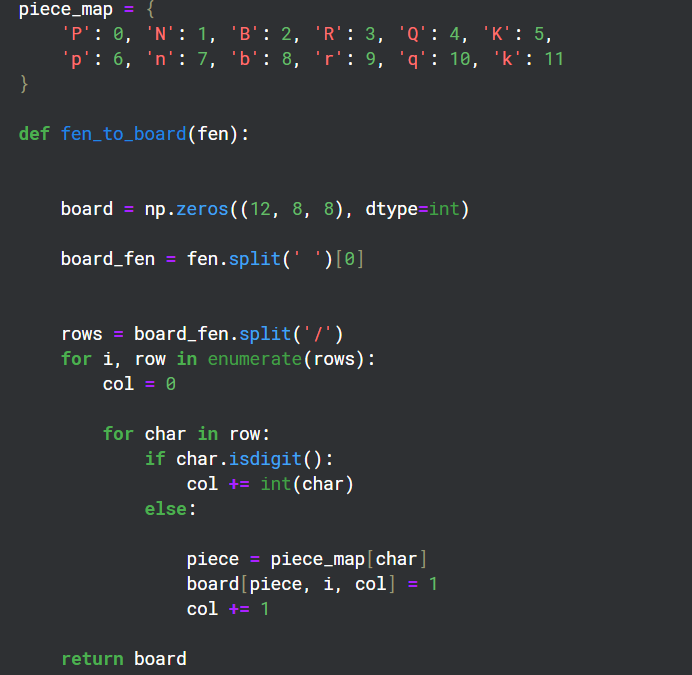
棋盘上有12种棋子,我创建了12个8×8的通道来表示每种棋子的状态。
环境包装器
import random class EnvCust: def __init__(self): self.env = make("chess", debug=True) self.game = game(self.env.state[0]['observation']['board']) self.action_space = list(self.game.get_moves()) self.obs_space = fen_to_board(self.env.state[0]['observation']['board']) def get_action(self): return list(self.game.get_moves()) def get_obs_space(self): return fen_to_board(self.env.state[0]['observation']['board']) def step(self, action): reward = 0 g = game(self.env.state[0]['observation']['board']) if g.board.get_piece(game.xy2i(action[2:4])) == 'q': reward = 7 elif g.board.get_piece(game.xy2i(action[2:4])) in ('n', 'b', 'r'): reward = 4 elif g.board.get_piece(game.xy2i(action[2:4])) == 'p': reward = 2 g.apply_move(action) done = False if g.status == 2: done = True reward = 10 elif g.status == 1: done = True reward = -5 self.env.step([action, 'none']) self.action_space = self.get_action() if not self.action_space: done = True else: self.env.step(['none', random.choice(self.action_space)]) g = game(self.env.state[0]['observation']['board']) if g.status == 2: reward = -10 done = True self.action_space = self.get_action() return self.env.state[0]['observation']['board'], reward, done
此包装器提供奖励机制和与环境交互的step函数。chessnut帮助获取合法走法和将死信息。奖励策略:将死得分,吃子得分,输棋扣分。
重放缓冲区
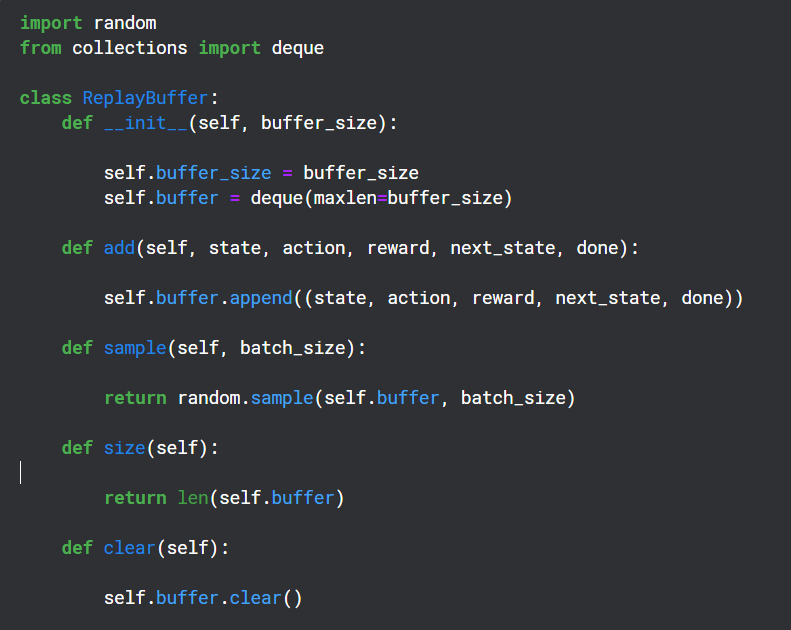
重放缓冲区存储(状态, 动作, 奖励, 下一状态)元组,用于目标网络的反向传播。
辅助函数
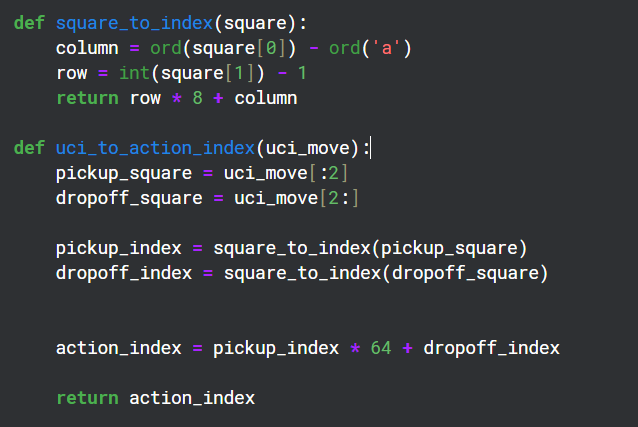
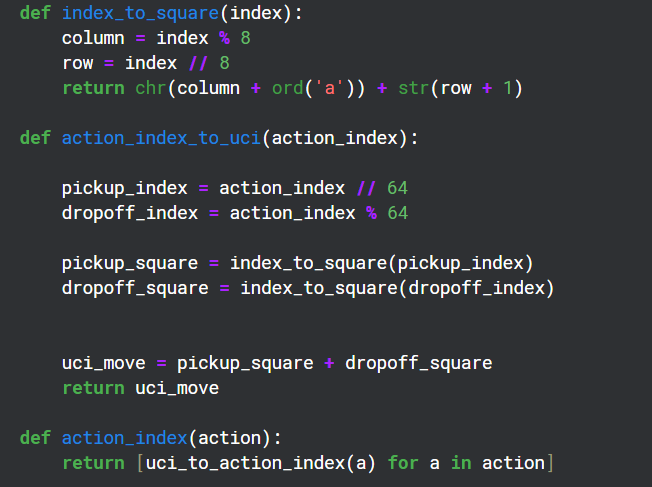
chessnut使用UCI格式(例如”a2a3″)表示动作。为了与神经网络交互,我将其转换为索引(64*64)。我知道并非所有索引都对应合法走法,但chessnut可以处理合法性,且这种方法足够简单。
神经网络结构
import torch import torch.nn as nn import torch.optim as optim class DQN(nn.Module): def __init__(self): super(DQN, self).__init__() self.conv_layers = nn.Sequential( nn.Conv2d(12, 32, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), nn.ReLU() ) self.fc_layers = nn.Sequential( nn.Flatten(), nn.Linear(64 * 8 * 8, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, 4096) ) def forward(self, x): x = x.unsqueeze(0) x = self.conv_layers(x) x = self.fc_layers(x) return x def predict(self, state, valid_action_indices): with torch.no_grad(): q_values = self.forward(state) q_values = q_values.squeeze(0) valid_q_values = q_values[valid_action_indices] best_action_relative_index = valid_q_values.argmax().item() best_action_index = valid_action_indices[best_action_relative_index] return valid_q_values[best_action_relative_index], best_action_index
神经网络使用卷积层处理12通道输入,并使用合法动作索引过滤输出。
代理实现
# ... (假设ReplayBuffer, fen_to_board, uci_to_action_index等函数已定义) ... device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = DQN().to(device) target_network = DQN().to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) replay_buffer = ReplayBuffer(buffer_size=10000) epsilon = 0.5 gamma = 0.99 batch_size = 15 def train(episodes): for ep in range(1, episodes + 1): print('Episode Number:', ep) myenv = EnvCust() done = False state = myenv.get_obs_space() i = 0 while not done and i < batch_size: # ... (action selection and step logic) ... # ... (replay buffer update) ... i += 1 if ep % 5 == 0: target_network.load_state_dict(model.state_dict())
这是一个非常基础的模型,效果肯定不好,但这有助于我理解DQN的工作原理。

请注意,代码中省略了一些函数的定义(例如ReplayBuffer, fen_to_board, uci_to_action_index, action_index),因为它们比较长,而且本文的重点是架构和思路。 要运行这段代码,需要补充这些函数的实现。 此外,这个模型过于简化,实际应用中需要更复杂的网络结构、训练策略和超参数调整才能获得更好的效果。
以上就是使用 DQN 构建国际象棋代理的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

