利用高效抓取google搜索结果,洞悉数据趋势!
Google每天处理超过85亿次搜索,占据全球搜索引擎市场91%的份额,蕴藏着巨大的数据价值,可用于SEO优化、竞争分析、潜在客户开发,以及高级LLM模型的训练和自然语言处理能力的提升。然而,直接抓取Google数据并非易事,需要专业的技术和强大的基础设施。本文将引导您使用Python和BeautifulSoup库,轻松构建自己的Google搜索结果抓取工具。

Google搜索结果解析
Google搜索结果根据用户查询,利用强大的自然语言处理技术,提供包含有机结果、特色片段(如“人们也问”、“相关搜索”和知识图谱)的综合信息。
立即学习“”;
Python抓取的应用场景
- SEO排名和关键词追踪
- 本地企业搜索
- LLM引擎构建
- 潜在趋势挖掘
选择Python?
Python凭借其强大的HTTP请求处理能力、简洁的语法、丰富的库(如Scrapy、Requests和BeautifulSoup)以及活跃的开发者社区支持,成为网页抓取的首选语言。其易于学习和扩展性,使其成为抓取Google等网站的理想选择。
Python抓取Google搜索结果步骤
本节将创建一个基本的Python脚本,检索前10个Google搜索结果,包含标题、链接、显示链接、描述和结果排名。
准备工作:
- 创建Python文件 (例如:scraper.py)
- 安装所需库:pip install requests beautifulsoup4
代码实现:
from bs4 import BeautifulSoup import requests headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'} url = 'https://www.google.com/search?q=python+tutorials&gl=us' response = requests.get(url, headers=headers) print(response.status_code) # 检查请求是否成功 (200表示成功) soup = BeautifulSoup(response.text, 'html.parser') organic_results = [] i = 0 for el in soup.select(".g"): # 选择包含搜索结果的div元素 try: title = el.select_one("h3").text if el.select_one("h3") else "no title" displayed_link = el.select_one(".byrv5b cite").text if el.select_one(".byrv5b cite") else "no displayed link" link = el.select_one("a")["href"] if el.select_one("a") else "no link" description = el.select_one(".vwic3b").text if el.select_one(".vwic3b") else "no description" organic_results.append({ "title": title, "displayed_link": displayed_link, "link": link, "description": description, "rank": i + 1 }) i += 1 except Exception as e: print(f"Error parsing element: {e}") print(organic_results)
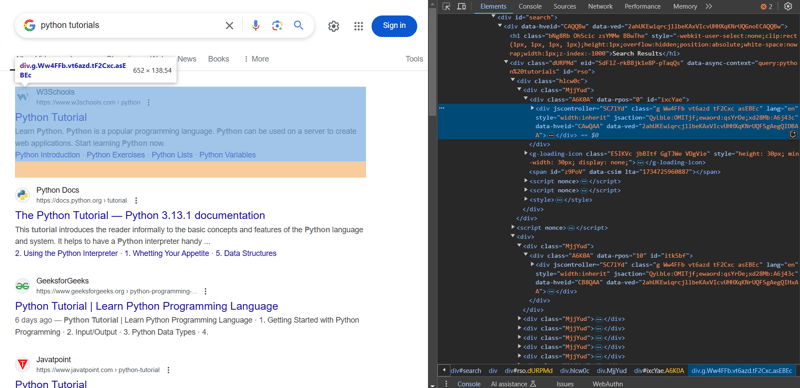
使用API提升稳定性
为了避免IP被封禁以及更稳定地进行大规模抓取,建议使用专业的SERP API,例如APIforSEO。注册后获取API密钥,即可通过API轻松获取Google搜索结果数据,包括高级功能片段。
总结
掌握Google搜索结果抓取技术,能够帮助企业和研究人员有效利用Google海量数据,提升决策效率,把握市场趋势。本文提供的Python脚本和API方案,将帮助您轻松开启数据分析之旅。
以上就是使用 Python 抓取 Google 搜索结果的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

