算法是解决问题的指令集,其执行速度和各不相同。编程中,许多算法都基于和排序。本文将介绍几种数据检索和排序算法。
线性搜索
假设有一个数组 [20, 500, 10, 5, 100, 1, 50],需要查找数字 50。线性搜索算法会逐个检查数组中的每个元素,直到找到目标值或遍历完整个数组。
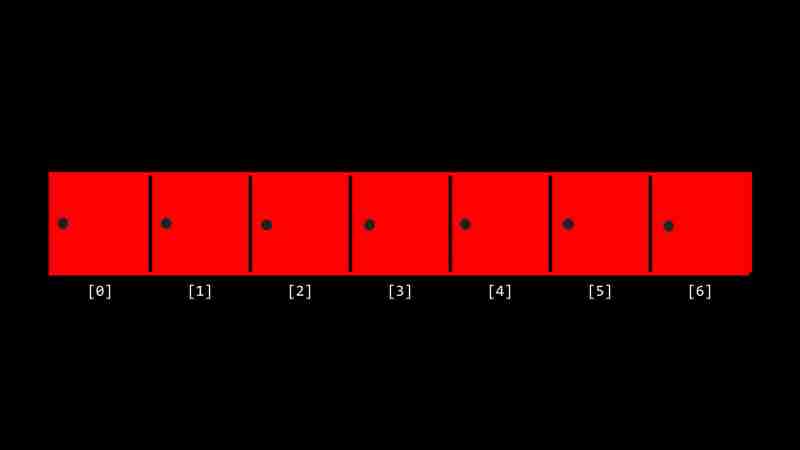
算法流程图如下:
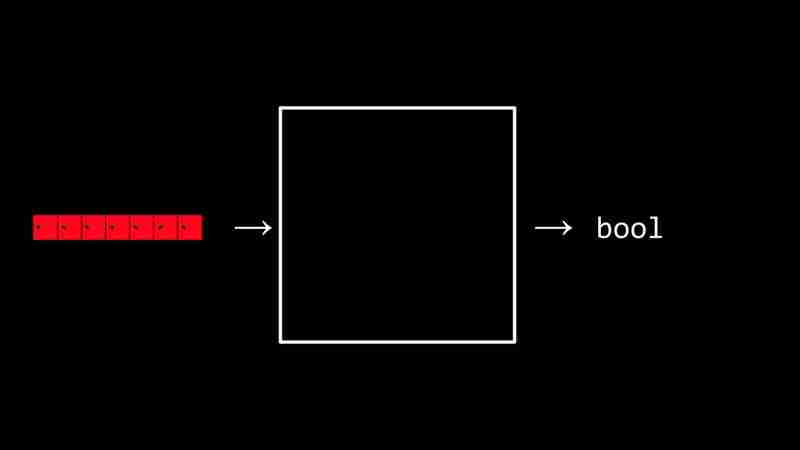
线性搜索的伪代码如下:
检查每个元素: 如果找到目标值: 返回 true 返回 false
登录后复制
C语言实现:
#include <cs50.h> #include <stdio.h> int main(void) { int numbers[] = {20, 500, 10, 5, 100, 1, 50}; int n = get_int("number: "); for (int i = 0; i < 7; i++) { if (numbers[i] == n) { printf("true "); return 0; } } printf("false "); return 0; }
登录后复制
线性搜索的时间复杂度为 O(n)。
二分查找
二分查找算法适用于已排序的数组。它通过不断缩小搜索范围来提高效率。
二分查找的伪代码如下:
如果数组为空: 返回 false 如果中间元素等于目标值: 返回 true 如果中间元素大于目标值: 在左半部分继续查找 否则: 在右半部分继续查找
登录后复制
二分查找的时间复杂度为 O(log n)。
大O表示法
大O表示法用于描述算法的时间复杂度。下图展示了不同时间复杂度的曲线:
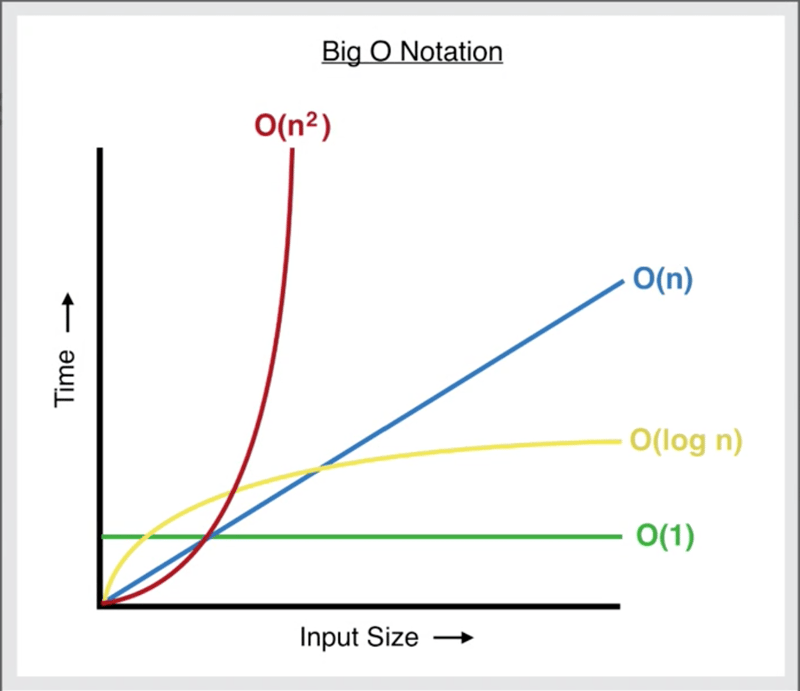
x轴表示输入数据量,y轴表示求解时间。O(log n) 表示最优时间复杂度,O(n²) 表示最差时间复杂度。
排序算法
排序算法用于将无序数据转换为有序数据。已排序的数据可以提高搜索效率,例如二分查找。
选择排序
选择排序算法的伪代码如下:
对于每个元素: 找到剩余元素中的最小值 将最小值与当前元素交换
登录后复制
选择排序的时间复杂度为 O(n²),无论数据是否已排序。
冒泡排序算法通过重复比较和交换相邻元素来排序数据。
冒泡排序算法的伪代码如下:
重复 n-1 次: 对于每个元素: 如果相邻元素顺序错误: 交换它们 如果未进行任何交换: 结束排序
登录后复制
冒泡排序的时间复杂度在最坏情况下为 O(n²),在最好情况下为 O(n)。
本文基于cs50x 2024源码。
以上就是CS-第 3 周的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

