介绍
当我在互联网上搜索某些内容时,我经常发现英语内容比法语内容全面得多。
虽然考虑到世界上讲英语的人数与讲法语的人数相比(大约多 4 到 5 倍),这似乎是显而易见的,但我想测试这个假设并对其进行量化。
tldr:平均而言,维基百科上的英文文章比法文文章包含的信息多 19%。
此分析的源代码可在此处获取:https://hub.com/jverneaut/wikipedia-analysis/
协议
维基百科是全球网络上最大的优质内容来源之一。
点击下载“”;
在撰写本文时,英文版拥有超过 6,700,000 篇独特文章,而法文版只有 2,500,000 篇。我们将使用这个语料库作为我们学习的基础。
使用蒙特卡罗方法,我们将从维基百科中针对每种语言随机抽取文章,并计算该语料库的平均字符长度。有了足够多的样本,我们应该得到接近现实的结果。
由于wikimedia api没有提供获取文章字符长度的方法,我们将通过以下方式获取此信息:
- 通过维基媒体 api 检索大量文章样本的字节大小。
- 使用蒙特卡罗方法从一小部分文章样本中估计每个字符的字节数。
- 使用步骤 2 中获得的每字符字节估计值检索大量文章的字符数。
由于我们使用蒙特卡罗方法来估计每个字符的字节数,因此我们需要尽可能多的文章数来尽量减少与实际数量的偏差。
维基媒体 api 文档指定了这些限制:
- 每个请求的随机文章不超过 500 篇。
- 每个请求的文章内容不得超过 50 条。
考虑到这些限制,并作为精度和查询执行时间之间的折衷,我选择对每种语言采样 100,000 篇文章作为文章字节长度的参考,并选择 500 篇文章来估计每种语言每个字符的字节数。
局限性
目前,当要求提供文章内容时,维基媒体 api 会返回其自己的维基文本格式。这种格式不是纯文本,更接近 html。由于维基媒体上的所有语言都使用相同的格式,我估计我们可以依赖它而不影响我们最终结果的方向。
但是,某些语言比其他语言更冗长。例如,在法语中,我们说“comment ça va?” (15 个字符)与“你好吗?”相比(12 个字符)英文。这项研究没有解释这种现象。如果我们想解决这个问题,我们可以比较同一本书语料库的不同翻译,以建立语言的“密度”校正变量。在我的研究中,我没有找到任何数据提供适用于每种语言的比率。
不过,我确实发现了一篇非常有趣的论文,它比较了 17 种不同语言的信息密度以及它们的说话速度。其结论是,最“高效”的语言比效率最低的语言说得更慢,导致口头信息传输速率始终保持在每秒 39 位左右。
有趣。
获取每种语言文章的平均字节长度
如协议中所述,我们将使用维基百科 api 来检索给定语言的 500 篇随机文章。
def getrandomarticlesurl(locale): return "https://" + locale + ".wikipedia.org/w/api.php?action=query&generator=random&grnlimit=500&grnnamespace=0&prop=info&format=json" def getrandomarticles(locale): url = getrandomarticlesurl(locale) response = requests.get(url) return json.loads(response.content)["query"]["pages"]
这会给我们一个类似 { “id1”: { “title”: “…”, “length”: 1234 }, “id2”: { “title”: “…”, “length “: 5678 }, … } 我们可以用它来检索大量文章的大小(以字节为单位)。
然后对这些数据进行重新处理以获得下表:
| language | average length | … |
|---|---|---|
| en | 8865.33259 | |
| fr | 7566.10867 | |
| ru | 10923.87673 | |
| ja | 9865.59485 | |
| … |
乍一看,英语文章的字节长度似乎比法语文章的字节长度要大。同样,俄语的字节长度比任何其他语言的字节长度都大。
我们应该停止这个结论吗?不完全是。由于维基百科报告的长度是以字节为单位的长度,因此我们需要更深入地研究字符的编码方式以理解这些初始结果。
字母如何编码:utf-8 简介
什么是字节?
与你我不同,计算机没有字母的概念,更不用说字母表了。对于它来说,一切都被表示为 0 和 1 的序列。
在我们的十进制系统中,我们从 0 到 1,然后从 1 到 2,依此类推,直到 10。
对于使用二进制系统的计算机,我们从 0 到 1,然后从 1 到 10,然后从 10 到 11、100,等等。
这里有一个比较表,可以让您更清楚地了解:
| decimal | binary |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| … |
学习二进制远远超出了本文的范围,但是您可以看到,随着数字变大,其二进制表示形式比十进制表示形式“更宽”。
由于计算机需要区分数字,因此它将它们存储在称为字节的 8 个单位的小数据包中。一个字节由 8 位组成,例如 01001011。
utf-8如何存储字符
我们已经了解了如何存储数字,存储字母会稍微复杂一些。
我们在许多西方国家使用的拉丁字母使用 26 个字母的字母表。难道我们不能使用一个参考表,其中从 0 到 25 的每个数字对应一个字母吗?
| letter | index | binary index |
|---|---|---|
| a | 0 | 00000000 |
| b | 1 | 00000001 |
| c | 2 | 00000010 |
| … | … | … |
| z | 25 | 00011001 |
但是我们的字符不仅仅是小写字母。在这个简单的句子中,我们还包含大写字母、逗号、句点等。创建了一个标准化列表,将所有这些字符包含在一个字节中,称为 ascii 标准。
在计算的初期,ascii 足以满足基本用途。但是如果我们想使用其他字符怎么办?我们如何用西里尔字母(33 个字母)书写?这就是创建 utf-8 标准的原因。
utf-8 代表 unicode(通用编码字符集)t变换 format – 8 位。它是一种编码系统,允许计算机使用一个或多个字节存储字符。
为了指示数据使用了多少字节,该编码的前几位用于表示此信息。
| first utf-8 bits | number of bytes used |
|---|---|
| 0xxxxxx | 1 |
| 110xxxxx … | 2 |
| 1110xxxx … … | 3 |
| 11110xxx … … … | 4 |
以下内容也有其目的,但这再次超出了本文的范围。请注意,在我们的角色符合 x1111111 = 127 剩余可能性的情况下,至少可以使用单个位作为签名。
对于不使用重音符号的英语,我们可以假设文章中的大多数字符都会以这种方式编码,因此每个字符的平均字节数应该接近 1。
对于使用重音、变音符号等的法语,我们假设这个数字会更高。
最后,对于具有更广泛字母表的语言,例如俄语和日语,我们可以预期更高的字节数,这为解释之前获得的结果提供了一个起点。
获取每种语言文章的平均字符长度(以字节为单位)
现在我们了解了 wikipedia api 之前返回的值的含义,我们想要计算每种语言的每个字符的字节数,以便调整这些结果。
为此,我们使用不同的方式访问维基百科 api,该方式允许我们获取文章的内容及其字节长度。
为什么不直接使用这个api呢?
此 api 每次请求仅返回 50 个结果,而前一个返回 500 个结果。因此,在相同的时间内,我们可以通过这种方式获得 10 倍的结果。
更具体地说,如果使用第一种方法 api 调用需要 20 分钟,那么使用这种方法将需要 3 小时 20 分钟。
def getRandomArticlesUrl(locale): return "https://" + locale + ".wikipedia.org/w/api.php?action=query&generator=random&grnlimit=50&grnnamespace=0&prop=revisions&rvprop=content|size&format=json" def getRandomArticles(locale): url = getRandomArticlesUrl(locale) response = requests.get(url) return json.loads(response.content)["query"]["pages"]
综合这些数据后,以下是我们得到的摘录:
| language | bytes per character | … |
|---|---|---|
| en | 1.006978892420735 | |
| fr | 1.0243214042939228 | |
| ru | 1.5362439940531318 | |
| ja | 1.843857157700553 | |
| … |
所以我们的直觉是正确的:字母表较大的国家/地区会因其内容存储方式而扭曲数据。
我们还发现,正如我们之前假设的那样,法语平均使用比英语更多的字节来存储其字符。
结果
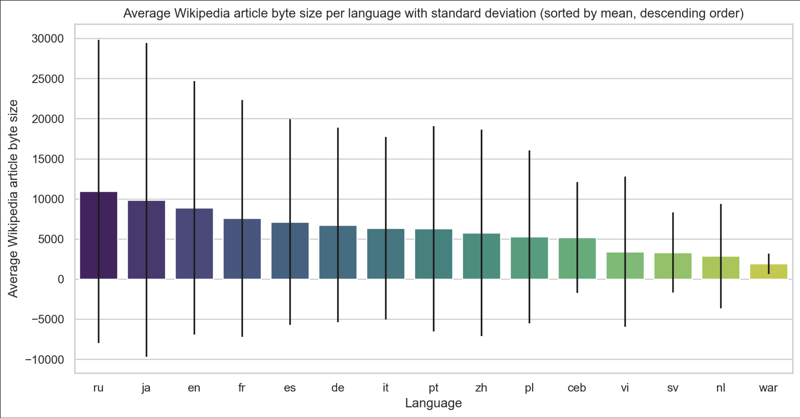
我们现在可以通过从以字节为单位的大小更改为以字符为单位的大小来更正数据,这给我们提供了下图:

我们的假设因此得到证实。
平均而言,英语是维基百科上每页内容最多的语言。接下来是法语,然后是俄语、西班牙语和德语。
此数据集的标准差(以黑条显示)很大,这意味着从最短的文章到最长的文章内容大小变化很大。因此,很难为所有文章建立一个普遍的真理,但这种趋势似乎仍然符合我个人对维基百科的体验。
如果您想要此实验的所有结果,我还创建了此表示形式,它将每种语言及其相对于其他语言的额外/较少内容的百分比进行比较。
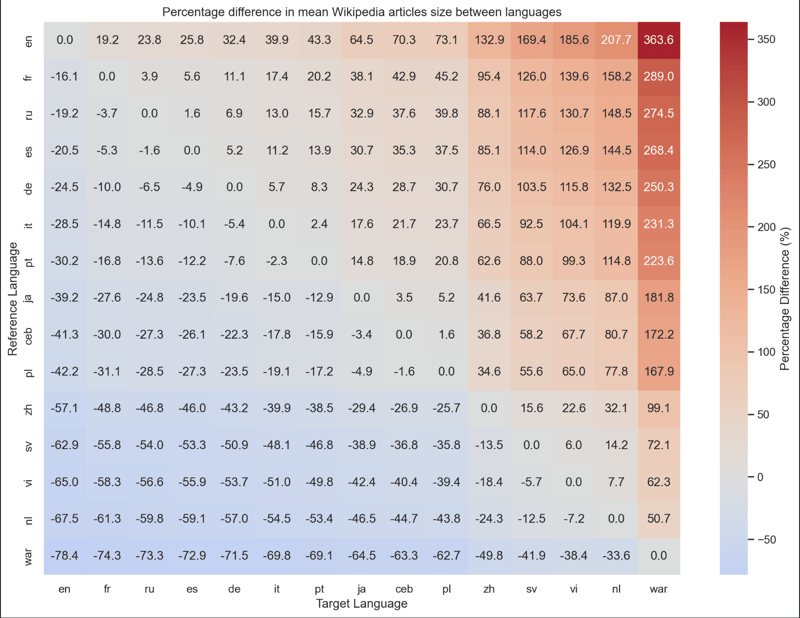
因此,我们得出的结论是,维基百科上的英文文章平均比法语文章包含的信息多 19%。
此分析的源代码可在此处获取:https://github.com/jverneaut/wikipedia-analysis/
以上就是哪个国家的维基百科内容最多?的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

